RAG(检索增强生成)详细流程解析
RAG,英文全称:Retrieval-Augmented Generation,中文翻译:检索增强生成
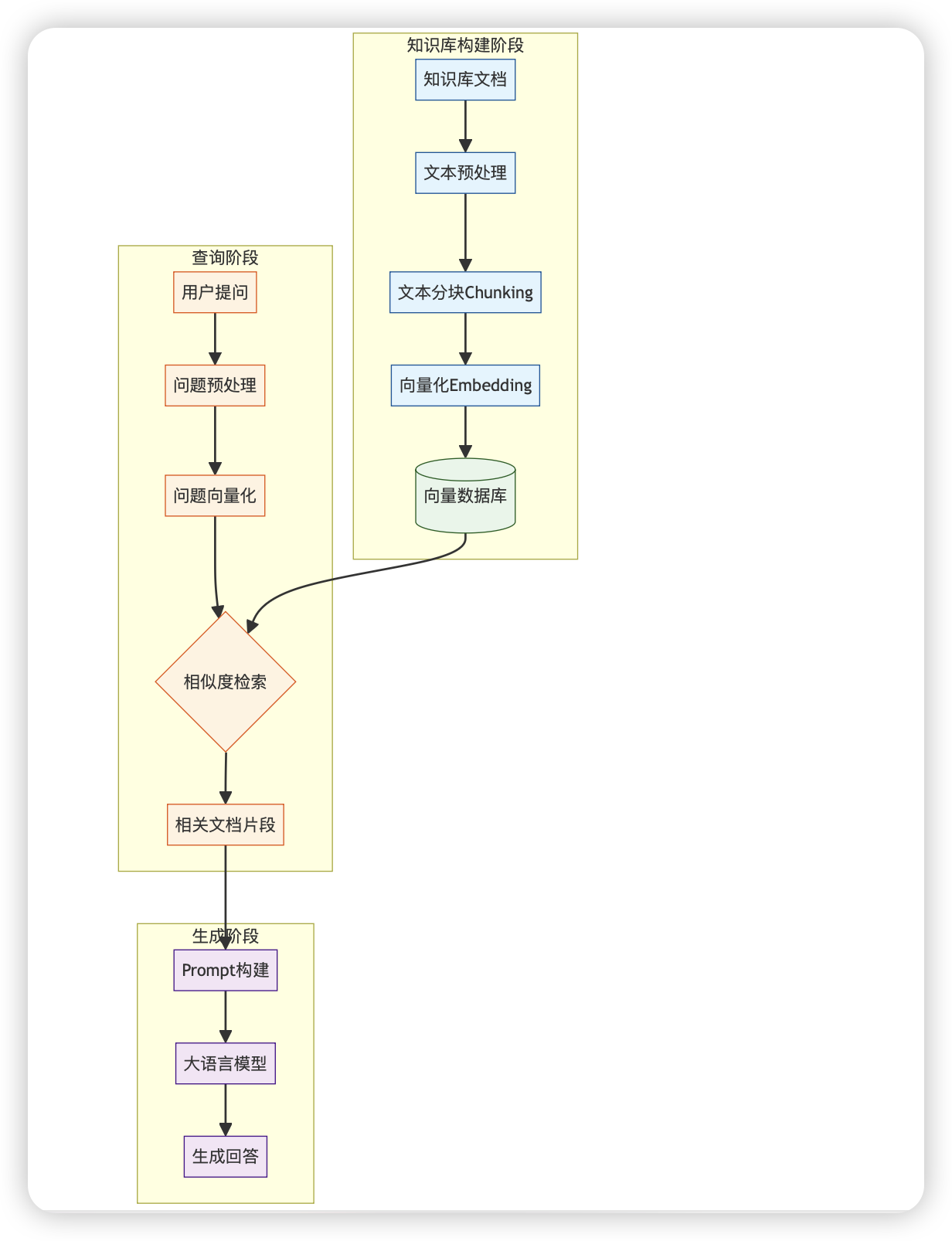
结合图中展示的流程,我将详细描述RAG的完整工作过程。RAG技术通过将外部知识与大语言模型结合,显著提升了生成内容的准确性、可靠性和相关性。
一、知识库构建阶段
这是RAG系统的基础环节,在图的右上方黄色区域展示:
1. 知识库文档收集
过程:收集各类文档资料,如PDF、网页、数据库记录、企业内部文档等
目的:建立丰富、权威的知识来源
特点:可以包含专业领域知识、最新信息或私有数据
2. 文本预处理
过程:对原始文档进行清洗、格式化和标准化
具体操作:
移除无关内容(如页眉页脚、广告)
纠正OCR错误
统一文本格式
处理特殊字符和符号
目的:提高后续处理的质量和效率
3. 文本分块(Chunking)
过程:将长文档切分成适当大小的文本片段
策略:
基于固定字符数/词数切分
基于语义边界切分(如段落、章节)
重叠切分(保证上下文连贯性)
重要性:合适的分块大小对检索效果至关重要
太大:检索精度下降,相关信息可能被稀释
太小:上下文信息不足,语义完整性受损
4. 向量化(Embedding)
过程:使用预训练模型将文本块转换为高维向量表示
常用模型:
OpenAI的text-embedding-ada-002
Sentence-BERT
BGE、GTE等开源embedding模型
特点:
捕捉文本的语义信息
将文本映射到向量空间,使相似内容在空间中距离接近
5. 向量数据库存储
过程:将生成的向量及其对应的原文本存入向量数据库
常用数据库:
Pinecone
Milvus
Weaviate
Chroma
FAISS
功能:支持高效的向量相似度搜索,为后续检索提供基础
二、查询阶段
当用户提出问题时,系统执行以下步骤(图中左侧黄色区域):
1. 用户提问
输入:用户以自然语言形式提出问题
特点:可能包含各种表达方式、专业术语或模糊描述
2. 问题预处理
过程:对用户问题进行清洗和规范化
操作:
拼写纠正
停用词处理
关键词提取
查询重写(可选)
目的:提高检索准确性,处理用户输入中的噪声
3. 问题向量化
过程:使用与知识库文档相同的embedding模型将问题转换为向量
重要性:确保问题和文档在同一向量空间,使相似度计算有意义
注意点:必须使用与知识库构建阶段相同的embedding模型
4. 相似度检索
过程:在向量数据库中查找与问题向量最相似的文本块
算法:
余弦相似度
欧氏距离
点积
参数:
Top-k:返回相似度最高的k个结果
相似度阈值:过滤相似度低于某阈值的结果
优化:
混合检索(结合关键词和向量检索)
重排序(对初步检索结果进行二次排序)
5. 相关文档片段
结果:获取检索到的最相关文本块
处理:
去重
合并相邻或重叠片段
按相关性排序
目的:为下一阶段的回答生成提供知识支持
三、生成阶段
最后,系统利用检索到的信息生成回答(图中底部黄色区域):
1. Prompt构建
过程:将用户问题和检索到的相关文档组合成结构化提示
策略:
明确指示模型使用提供的上下文
设置回答格式要求
添加引用要求
处理无法回答情况的指导
示例结构:
基于以下信息回答用户问题: [相关文档片段1] [相关文档片段2] ... 用户问题:[用户原始问题] 请仅使用提供的信息回答。如果信息不足,请明确说明。
2. 大语言模型调用
过程:将构建好的prompt发送给大语言模型
模型选择:
OpenAI的GPT系列
Claude
Llama系列
其他开源或私有大语言模型
参数设置:
温度(temperature):控制创造性
最大长度:控制回答长度
Top-p/Top-k:控制词汇选择多样性
3. 生成回答
过程:模型基于prompt和检索到的信息生成回答
特点:
结合检索到的专业知识
保持大语言模型的自然语言能力
可以包含引用或来源标注
后处理(可选):
事实性检查
格式优化
添加引用链接
RAG系统的优势
知识更新:知识库可以独立更新,无需重新训练模型
减少幻觉:通过提供外部知识,显著减少模型生成的虚假信息
可追溯性:回答可以追溯到具体的知识来源
领域适应:通过构建专业知识库,使通用模型适应特定领域
成本效益:比完全微调大语言模型更经济高效
RAG系统的挑战与优化
检索质量:检索结果的相关性直接影响回答质量
上下文长度限制:大语言模型的上下文窗口限制了可提供的信息量
知识冲突:检索到的信息可能相互矛盾
计算资源:大规模向量检索和模型调用需要较高计算资源
通过这个完整流程,RAG系统能够结合外部知识库的专业性和大语言模型的生成能力,提供更准确、更可靠的回答,特别适合需要最新信息、专业知识或特定领域应用的场景。